
Inicio
En base a los datos obtenidos del código de extracción presente en este repo, vamos generar 5 visuales sobre la pandemia en Argentina, trabajando con el recorte de afectados extraído del SISA.
Como éste es un documento abierto con fines pedagógicos, la propuesta de cada vizualización es sintentizar una forma de organizar la información y con ello dar cuenta de diversos indicadores de la pandemia en nuestro país.
Avanzamos cargando las librerías y el set de datos que descargamos y guardamos con fst.
library(tidyverse)
library(lubridate)
library(dplyr)
library(fst)
library(ggplot2)
library(glue)
options(scipen=1000)
ar_positivos <- read_fst("ar_positivos.fst")Armemos un primer histograma con la totalidad de los datos obtenidos, se trata de la totalidad de los afectados COVID-19 en argentina entre los años 2020 y 2021 agrupados por mes:
hist <- ar_positivos %>%
ggplot(aes(ar_positivos$fecha)) +
geom_histogram(col="steelblue", aes(fill=..count..))+
scale_fill_gradient2(low='darkgreen', mid='steelblue',
high='darkblue', midpoint=6,
name='ar_positivos')+
labs(title =
"Afectación COVID-19 en Argentina agrupada por mes (20/21)",
x= "Referencia temporal 20/21",
y= "Afectados mensuales.")+
guides(fill=guide_legend(title="Ref a/mensuales"), colour =
guide_legend(reverse=F))+
theme_bw() +
theme(plot.title = element_text(hjust = 0.5, size = 8.4,
lineheight=.7,face="bold"),
axis.text.x = element_text(angle = 45, size = 8),
axis.title.x = element_text(size = 8),
axis.title.y = element_text(size = 8),
legend.title = element_text(color = "black", size = 8),
legend.text = element_text(angle = 45,
color = "black", size = 8),legend.position="bottom")Inmprimimos:
hist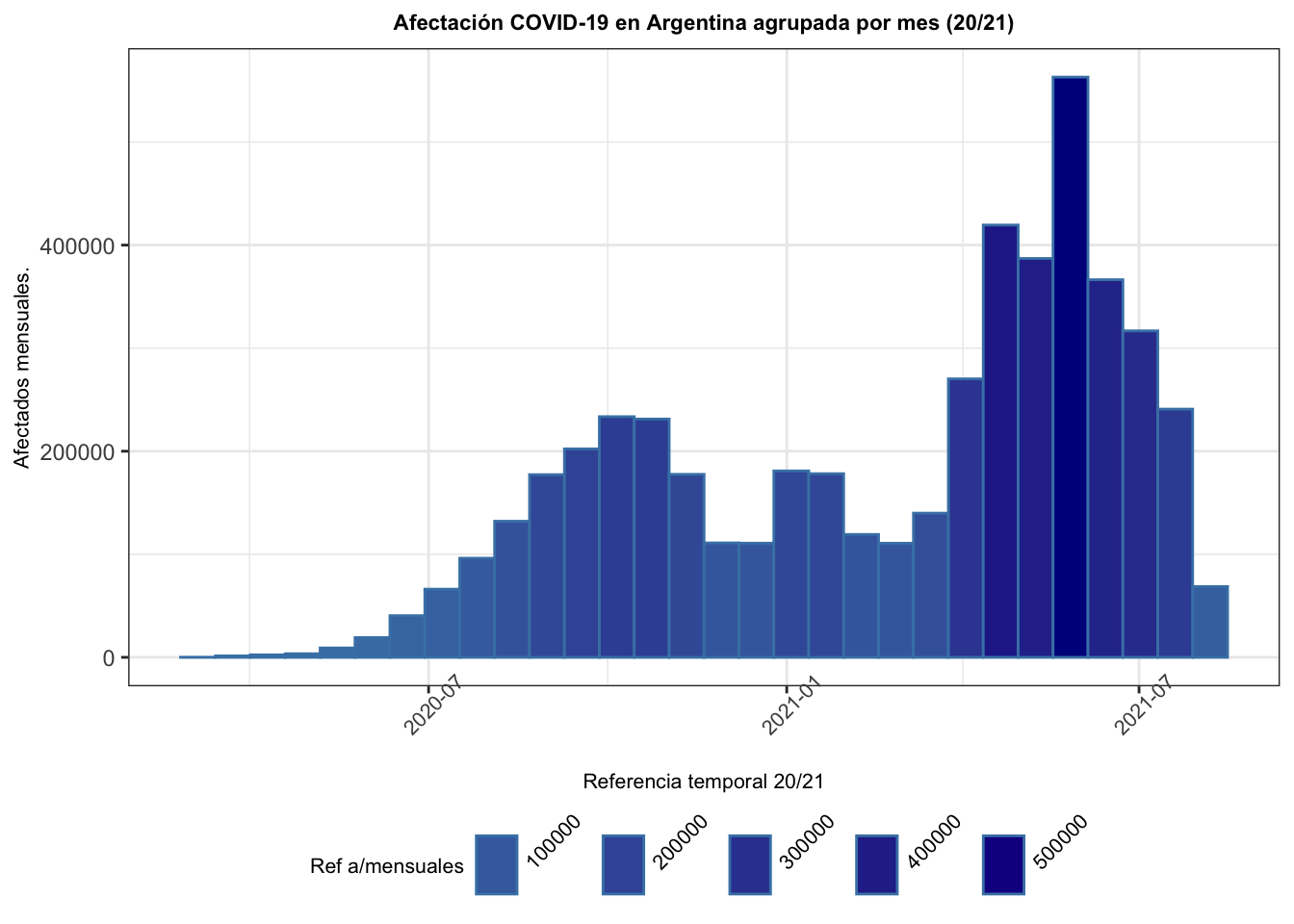
Con esta primera visual de la afectación COVID-19 en clave temporal se pueden apreciar claramente las denominadas primera y segunda “ola de contagios” en los años 2020 y 2021 respectivamente en la Argentina.
Enriqueciendo los datos
Una vez que tenemos el primer recorte de los datos, vamos crear nuevas variables ponderadas para enriquecer nuestro abordaje. Calcular la incidencia y mortalidad por 100.000 habitantes junto con la letalidad son operaciones relevantes para pensar el impacto del virus en un territorio determinado y compararlo con otros.
Para el caso presentado nos interesa nos interesa hacer un desagregado a escala federal. Para eso vamos a utilizar un vector con datos poblacionales por provincia que coadyuvará al enriquecimiento de nuestra información.
Levantamos el vector con los datos de población:
master <-read_csv("master.csv") Generamos nuestro código con los nuevos estadísticos;
provinciascovid <- ar_positivos %>%
group_by(provincia) %>%
summarise(casos = n(),
fallecimientos = sum(fallecido=='SI'),
intensivos = sum(cuidado_intensivo =='SI'),
asistencia_respi =
sum(asistencia_respiratoria_mecanica=='SI'),
letalidad = fallecimientos/casos * 100)%>%
left_join(master)%>%
mutate(casosmil = 1e5*casos/poblacion,
muertesmil = 1e5*fallecimientos/poblacion)De esta forma ya podemos acceder a los principales estadísticos epidemiológicos por provincia: afectados, fallecidos, variables ponderadas, etc.
Imágenes de la pandemia…
Detengamonos inicialmente en el caso de los datos acumulados de afectados e incidencia del virus COVID-19 cada 100.000 habitantes por provincia argentina.
Armamos nuestro gráfico de afectados:
plot1 <- provinciascovid %>%
select(provincia, casos)%>%
mutate_if(is.numeric, round, digits=1)%>%
filter(!provincia=="SIN ESPECIFICAR") %>%
arrange(desc(casos))%>%
ggplot(aes(reorder(provincia,casos),
casos, fill = casos)) +
geom_bar(stat = 'identity', alpha=0.9) +
scale_fill_viridis_c(option = "viridis") +
geom_label(aes(label=casos), fontface = "bold",
color ="grey",
size=2 ,position=position_dodge(width=0),
vjust=0.0)+
coord_flip()+
labs(title = "Afectados COVID-19 acumulados 20/21",
x= "Provincias Argentinas",
y= "Afectados",
fill = "Ref:")Lo vemos;
plot1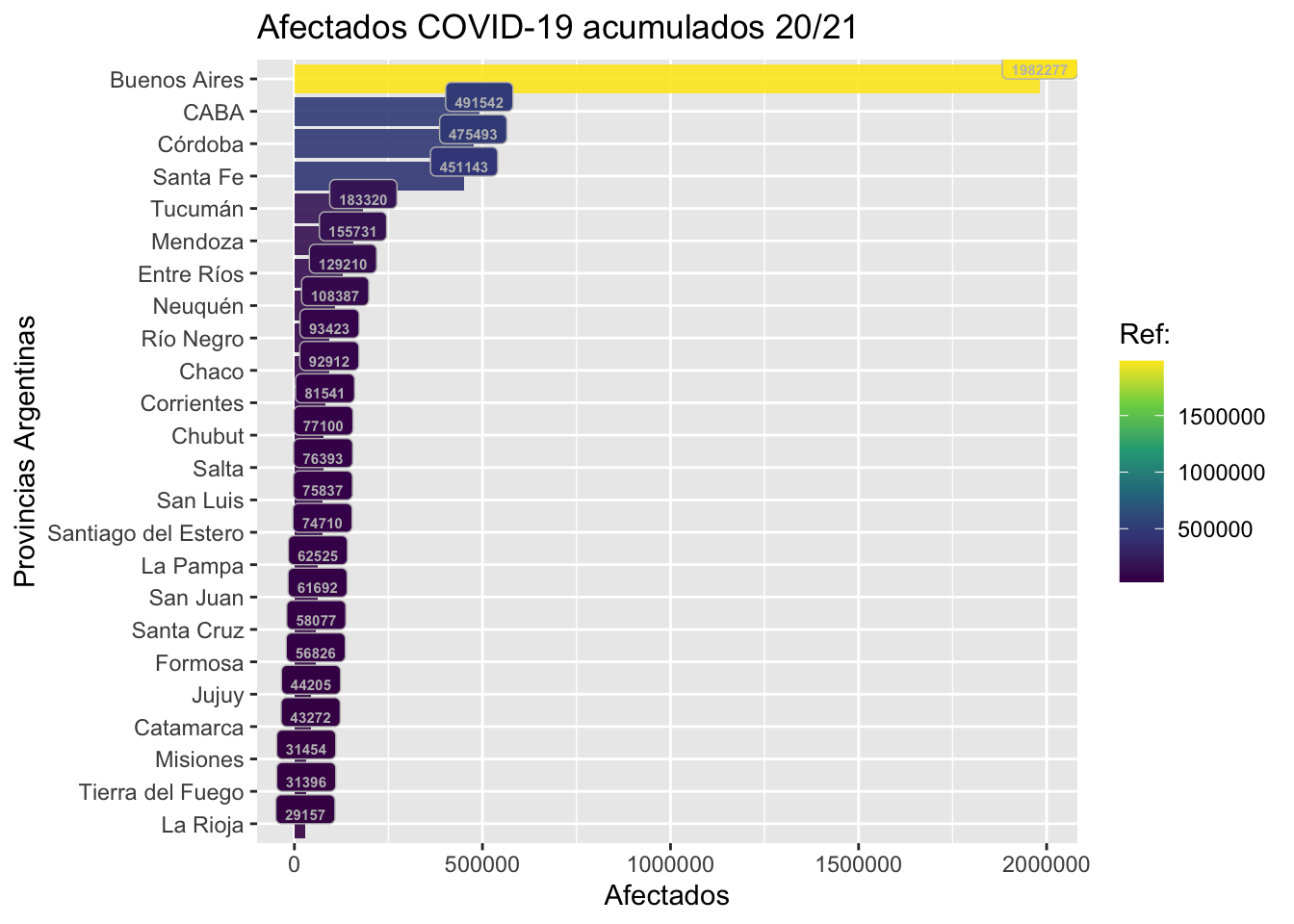
Ahora, repetimos el proceso con la variable de incidencia COVID-19 por 100.000 habitantes. En este caso vamos a darle un mejor formato al gráfico:
plot2 <- provinciascovid %>%
select(provincia, casosmil)%>%
mutate_if(is.numeric, round, digits=1)%>%
filter(!provincia=="SIN ESPECIFICAR") %>%
arrange(desc(casosmil))%>%
ggplot(aes(reorder(provincia,casosmil),
casosmil, fill = casosmil)) +
geom_bar(stat = 'identity', alpha=0.9) +
scale_fill_viridis_c(option = "cividis") +
geom_label(aes(label=casosmil), fontface = "bold",
color ="white",
size=2 ,position=position_dodge(width=0.1), vjust=0.0)+
coord_flip()+
labs(title =
"Afectados COVID-19 acumulados cada 100.000 abitantes(20/21)",
x= "Provincias Argentinas",
y= "Afectados c/100.000 habitantes",
fill = "Ref:") +
theme(plot.title = element_text(hjust = 0.5,
size = 11, lineheight=.7, face="bold"),
plot.subtitle = element_text(hjust = 0.5, size = 9,
lineheight=.7, face="bold"),
axis.text.x = element_text(angle = 45, size = 8),
axis.title.x = element_text(size = 8),
axis.title.y = element_text(size = 8),
legend.title = element_text(color = "black",
size = 8),legend.text = element_text(color = "black",
size = 8),legend.position="right")Y lo mostramos:
plot2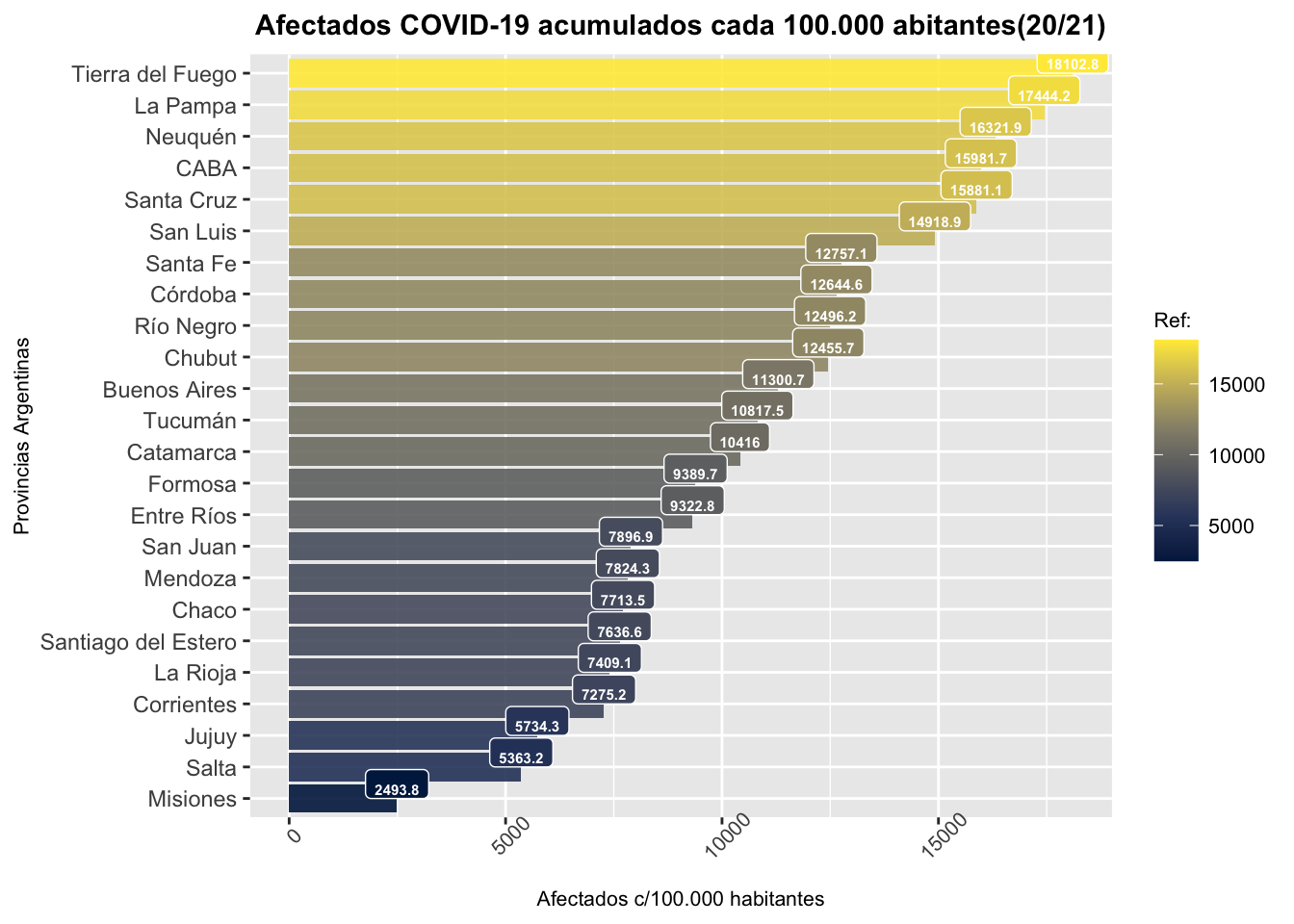
La lectura comparada de ambas gráficas da cuenta, por ejemplo, de una clara diferencia entre el ordenamiento de provincias que deviene al computar la afectación nominal o bien la ponderación por cien mil habitantes. Tengamos presente que depende de nuestros objetivos de investigación la eleccion de una, otra, o más variables.
Para seguir abriendo posibles ángulos de indagación con nuestros datos, vamos a reorganizarlos en clave espacio-temporal y poner nuestro foco en el promedio de edad de contagio diario del virus, prestando particular atención a las 4 provincias argentinas con más afectados (en términos nominales).
Armamos la data con los cortes y filtros que son de nuestro interés:
edad_afectados <- ar_positivos%>%
filter(!provincia=="SIN ESPECIFICAR") %>%
group_by(provincia, fecha)%>%
summarise(casos = n(),
muertos = sum(fallecido=='SI'),
edad_promedio = mean(edad, na.rm=T))%>%
mutate_if(is.numeric, round, digits=1)%>%
select(fecha, provincia, edad_promedio)%>%
filter(provincia%in%c("CABA", "Buenos Aires",
"Santa Fe", "Córdoba"))Generamos el gráfico:
plot_afectados <- edad_afectados %>%
ggplot(aes(x = fecha, y = edad_promedio)) +
geom_line(size = 0.1, alpha = 1)+
labs(title =
"Promedio diario de edad de los afectados por causas COVID-19",
x= "Referencia temporal",
y= "Edad promedio")+
theme_bw() +
facet_wrap(.~provincia, scales = "free")…y lo imprimimos en pantalla:
plot_afectados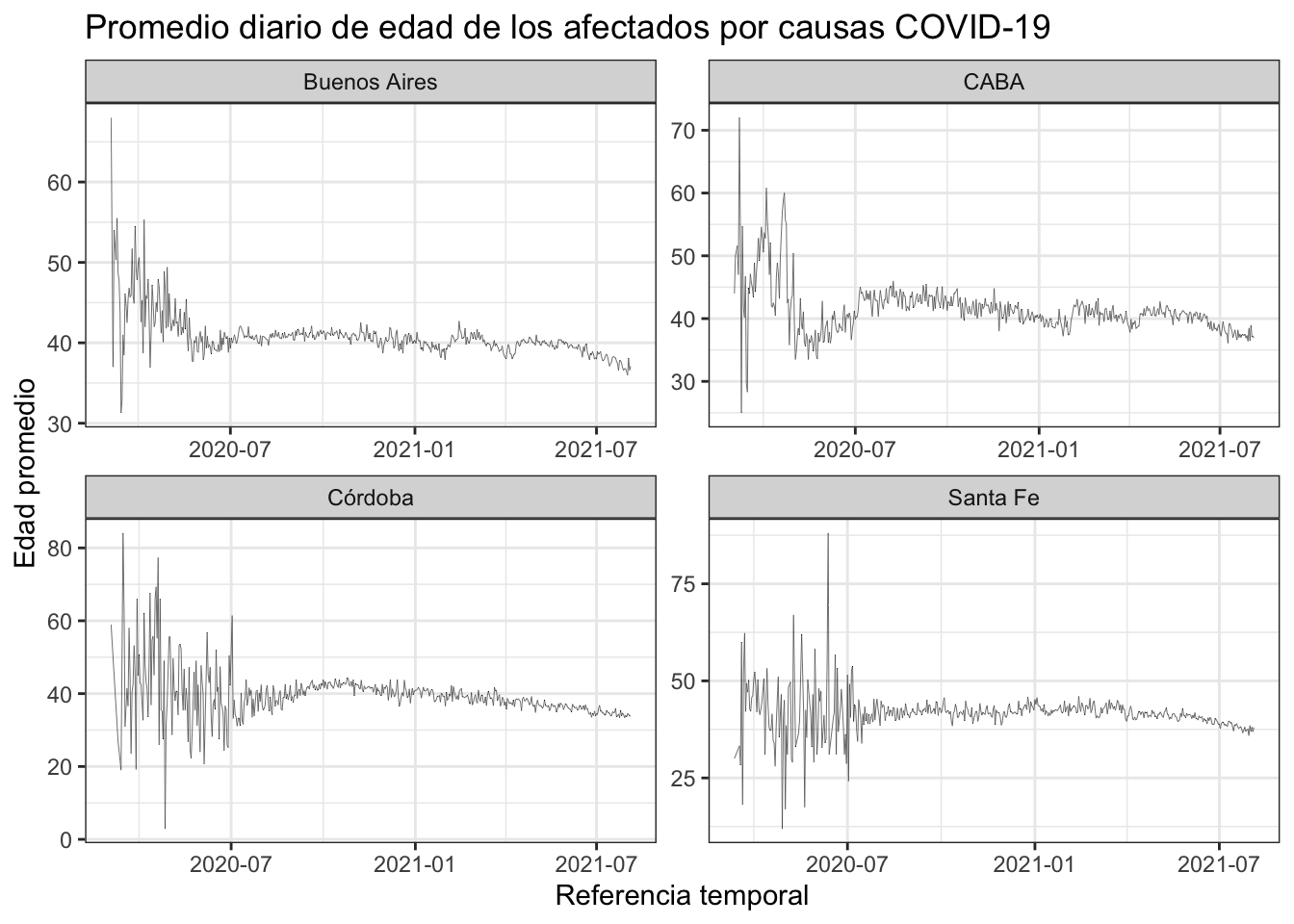
A primera vista vemos una baja progresiva en el promedio de edad contagio desde inicio de la pandemia a la fecha en las 4 provincias, siendo Buenos Aires la que presenta el menor promedio de edad (observar en la imagen como se reduce la escala el eje Y en BA particularmente).
Para hacer un zoom en el tema etáreo vamos a deternernos en la distribución porcentual de los afectados por grupo de edad, trabajaremos en este caso con variables factoriales.
Para dar con nuestro cometido vamos a generar una nueva variable “grupo de edad” a partir de los datos de edad que tenemos.
grupo_etareo <- ar_positivos%>%
filter(!provincia=="SIN ESPECIFICAR") %>%
filter(provincia %in% c("Buenos Aires",
"CABA", "Santa Fe",
"Córdoba"))%>%
mutate(grupoedad = case_when(
edad == NA ~ "sin datos",
edad >= -20 & edad <= 19 ~ "de 0 a 19 años",
edad >= 20 & edad <= 40 ~ "de 20 a 40 años",
edad >= 41 & edad <= 59 ~ "de 41 a 59 años",
edad >= 60 & edad <= 150 ~ "de 60 años en adelante")) %>%
ungroup() %>%
filter(!grupoedad=="sin datos") %>%
group_by(provincia,grupoedad) %>%
summarise(casos = n()) %>%
group_by(provincia) %>%
mutate(casost=sum(casos),
pct=casos/casost*100) %>%
mutate_if(is.numeric, round, digits=1)
grupo_etareo$grupoedad[is.na(grupo_etareo$grupoedad)]<- "sin datos"
grupo_etareo$grupoedad<-as_factor(grupo_etareo$grupoedad)
grupo_etareo$provincia<-as_factor(grupo_etareo$provincia)El script de nuestro plot;
plot_grup <- grupo_etareo%>%
ggplot(aes(fill=grupoedad, y=pct, x=provincia, label = pct)) +
geom_bar(stat="identity") +
scale_fill_viridis_d(option = "viridis") +
geom_text(size = 3,fontface = "bold",
color ="white",
position = position_stack(vjust = 0.5)) +
theme_bw() +
labs(title =
"Afectados COVID-19 por provincia y grupo etáreo",
x= "Provincia",
y= "% de afectados por grupo de edad",
fill="Grupo etáreo")Visualizamos:
plot_grup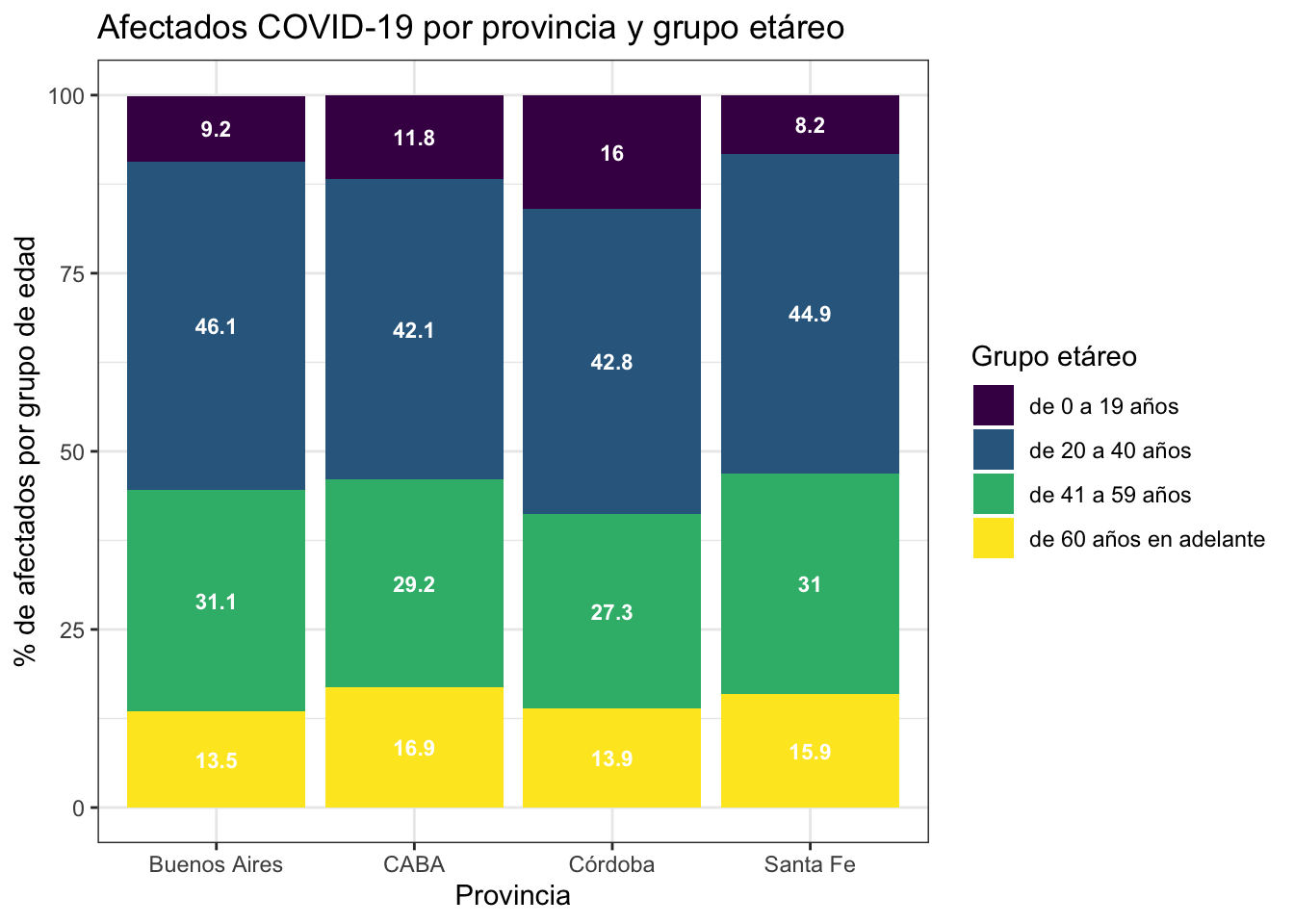
Siguiendo a Buenos Aires en el análisis comparativo sugerido, podremos observar finalmente que la provincia tiene una preminencia de contagios en los en los grupos estarios de 20-40 y 41-51 años.
Palabras Finales
Lo que hemos visto hasta aquí son recortes de experiencias prácticas del trabajo con datos, muchos de estos códigos sintetizan largos debates teóricos, metodológicos, estadísticos y tiempos de búsqueda de información sobre funciones y paquetes de R y afines.
Se ha procurado dar cuenta, de manera sucinta, de una serie de procedimientos y criterios para la manipulación y exploración de datos abiertos que bien pueden replicarse con otros sets y experiencias de desarrollo. Se espera que este documento opere como guía pedagogica en dicho sentido.
Cabrá destacar especialmente el uso y la importancia del paquete fst para gestionar con notable rapidez archivos de grandes dimensiones, habida cuenta, sobre todo, de la cualidad de objeto COVID-19 que se expande de manera constante.
Por ultimo, puede consultarse una shiny que desarollé para IDEP y opera con la misma logica que vimos en este documento.
Комментарии